Hadoop là một khung lập trình dựa trên Java, hỗ trợ xử lý và lưu trữ các tập dữ liệu cực lớn trên một nhóm các máy rẻ tiền. Đây là dự án mã nguồn mở lớn đầu tiên trong sân chơi dữ liệu lớn và được tài trợ bởi Apache Software Foundation.
Hadoop bao gồm bốn lớp chính:
Các Hadoop Cluster tương đối phức tạp để thiết lập, vì vậy dự án bao gồm một chế độ độc lập phù hợp để tìm hiểu về Hadoop, thực hiện các thao tác đơn giản và gỡ lỗi.
Trong hướng dẫn này, bạn sẽ cài đặt Hadoop ở chế độ độc lập và chạy một trong các chương trình MapReduce mẫu mà nó bao gồm để xác minh cài đặt.
Để làm theo hướng dẫn này, bạn sẽ cần:
sudo: Bạn có thể tìm hiểu thêm về cách thiết lập người dùng có các đặc quyền này trong hướng dẫn Thiết lập máy chủ ban đầu với Ubuntu 20.04 của chúng tôi.Bạn cũng có thể muốn xem Giới thiệu về các khái niệm và thuật ngữ dữ liệu lớn hoặc Giới thiệu về Hadoop
Khi bạn đã hoàn thành các điều kiện, hãy đăng nhập với tư cách là sudo user của bạn để bắt đầu.
Để bắt đầu, bạn sẽ cập nhật danh sách gói của chúng tôi và cài đặt OpenJDK, Bộ phát triển Java mặc định trên Ubuntu 20.04:
- sudo apt update
- sudo apt install default-jdk
Sau khi cài đặt xong, hãy kiểm tra phiên bản.
- java -version
Outputopenjdk version "11.0.13" 2021-10-19
OpenJDK Runtime Environment (build 11.0.13+8-Ubuntu-0ubuntu1.20.04)
OpenJDK 64-Bit Server VM (build 11.0.13+8-Ubuntu-0ubuntu1.20.04, mixed mode, sharing)
Đầu ra này xác minh rằng OpenJDK đã được cài đặt thành công.
Với Java sẵn có, bạn sẽ truy cập trang Bản phát hành Apache Hadoop để tìm bản phát hành ổn định gần đây nhất.
Điều hướng đến binary (nhị phân) cho bản phát hành bạn muốn cài đặt. Trong hướng dẫn này, bạn sẽ cài đặt Hadoop 3.3.1, nhưng bạn có thể thay thế số phiên bản trong hướng dẫn này bằng một trong những lựa chọn của bạn.
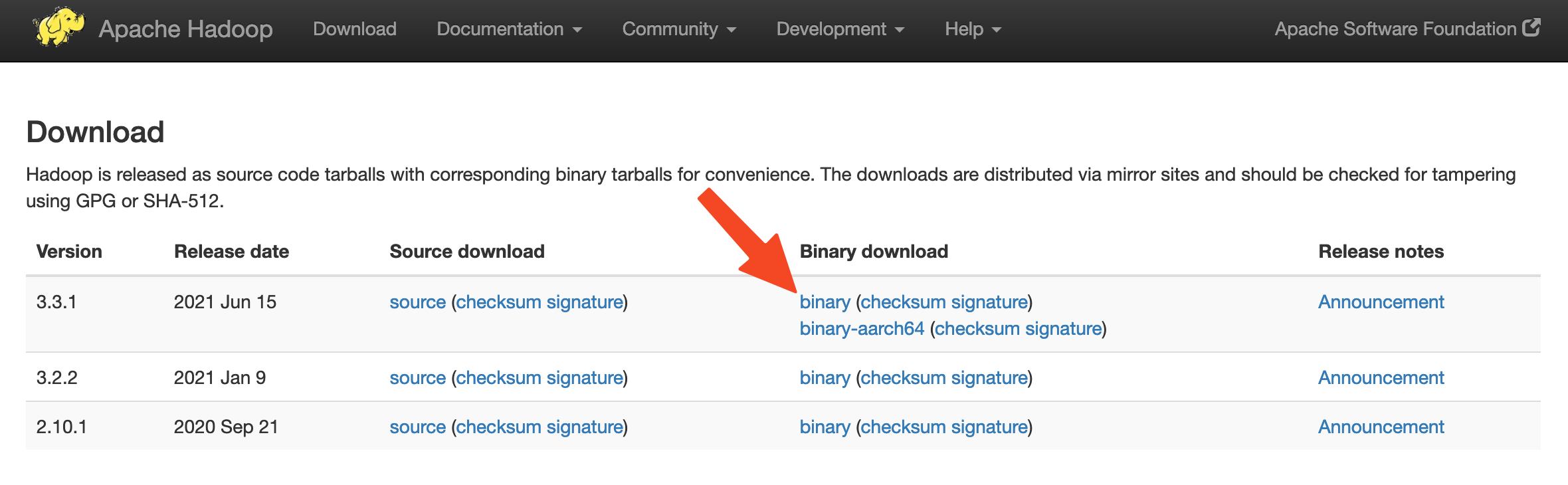
Trên trang tiếp theo, nhấp chuột phải và sao chép liên kết vào tệp nhị phân phát hành.
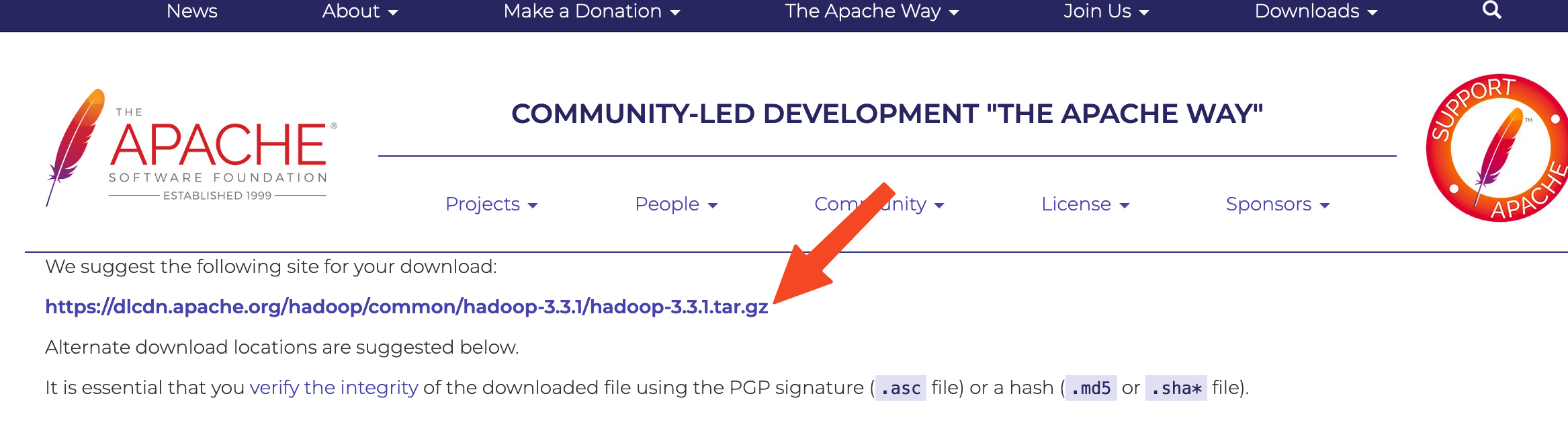
Trên máy chủ, bạn sẽ sử dụng wget để tìm nó:
- wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz
Lưu ý: Trang web Apache sẽ tự động chuyển hướng bạn đến máy nhân bản tốt nhất, vì vậy URL của bạn có thể không khớp với URL ở trên.
Để đảm bảo rằng tệp bạn đã tải xuống không bị thay đổi, bạn hãy kiểm tra nhanh bằng cách sử dụng SHA-512 hoặc Secure Hash Algorithm 512. Quay lại trang phát hành, sau đó nhấp chuột phải và sao chép liên kết tới tệp tổng kiểm tra cho bản nhị phân phát hành mà bạn đã tải xuống:
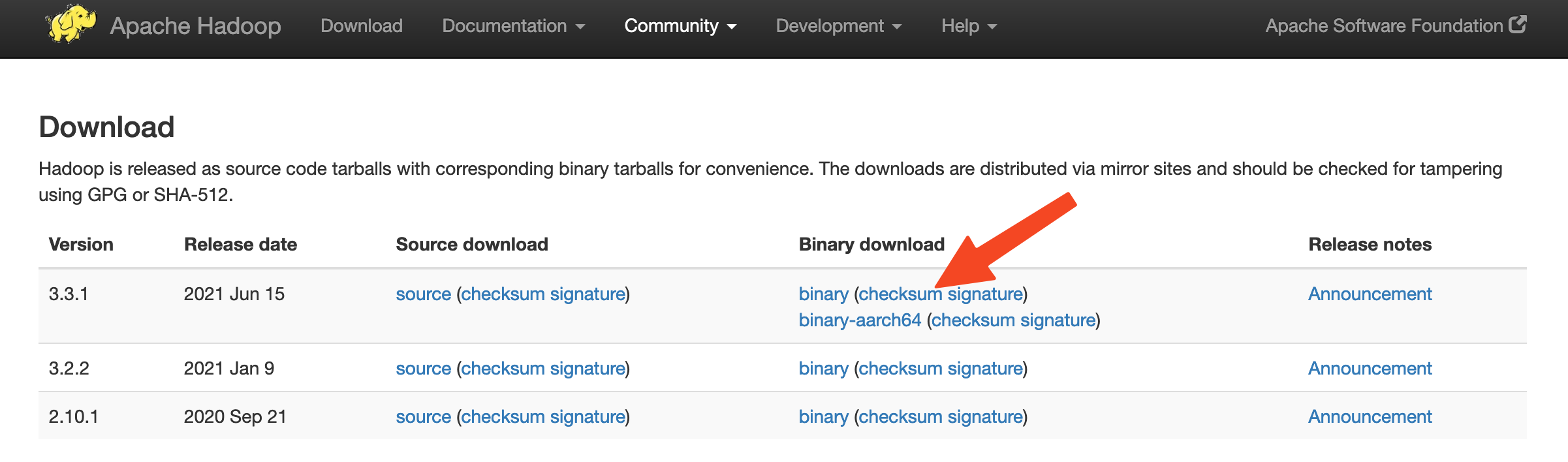
Một lần nữa, bạn sẽ sử dụng wget trên máy chủ của chúng tôi để tải xuống tệp:
- wget https://downloads.apache.org/hadoop/common/hadoop-3.3.1/hadoop-3.3.1.tar.gz.sha512
Sau đó chạy xác minh:
- shasum -a 512 hadoop-3.3.1.tar.gz
Output2fd0bf74852c797dc864f373ec82ffaa1e98706b309b30d1effa91ac399b477e1accc1ee74d4ccbb1db7da1c5c541b72e4a834f131a99f2814b030fbd043df66 hadoop-3.3.1.tar.gz
So sánh giá trị này với giá trị SHA-512 trong tệp .sha512:
- cat hadoop-3.3.1.tar.gz.sha512
...
SHA512 (hadoop-3.3.1.tar.gz) = 2fd0bf74852c797dc864f373ec82ffaa1e98706b309b30d1effa91ac399b477e1accc1ee74d4ccbb1db7da1c5c541b72e4a834f131a99f2814b030fbd043df66
...
Đầu ra của lệnh bạn chạy với tệp bạn đã tải xuống từ máy nhân bản phải khớp với giá trị trong tệp bạn đã tải xuống từ apache.org.
Bây giờ bạn đã xác minh rằng tệp không bị hỏng hoặc bị thay đổi, bạn có thể trích xuất nó:
- tar -xzvf hadoop-3.3.1.tar.gz
Sử dụng lệnh tar với cờ -x để trích xuất, -z để giải nén, -v cho đầu ra dài và -f để xác định rằng bạn đang giải nén từ một tệp.
Cuối cùng, bạn sẽ di chuyển các tệp đã giải nén vào /usr/local, nơi thích hợp cho phần mềm được cài đặt cục bộ:
- sudo mv hadoop-3.3.1 /usr/local/hadoop
Với phần mềm tại chỗ, bạn đã sẵn sàng thiết lập cấu hình môi trường của nó.
Hadoop yêu cầu bạn đặt đường dẫn đến Java, dưới dạng một biến môi trường hoặc trong tệp cấu hình Hadoop.
Đường dẫn đến Java, /usr/bin/java là một liên kết tượng trưng tới /etc/alternatives/java, đây là một liên kết tượng trưng đến nhị phân Java mặc định. Bạn sẽ sử dụng readlink với cờ -f để theo dõi mọi liên kết biểu tượng trong mọi phần của đường dẫn, một cách đệ quy. Sau đó, bạn sẽ sử dụng sed để cắt bin/java khỏi đầu ra để cung cấp giá trị chính xác cho JAVA_HOME.
Để tìm đường dẫn Java mặc định:
- readlink -f /usr/bin/java | sed "s:bin/java::"
Output/usr/lib/jvm/java-11-openjdk-amd64/
Bạn có thể sao chép đầu ra này để đặt trang chủ Java của Hadoop thành phiên bản cụ thể, điều này đảm bảo rằng nếu Java mặc định thay đổi, giá trị này sẽ không được chấp nhận. Ngoài ra, bạn có thể sử dụng lệnh readlink trong tệp để Hadoop tự động sử dụng bất kỳ phiên bản Java nào được đặt làm mặc định của hệ thống.
Để bắt đầu, hãy mở hadoop-env.sh:
- sudo nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh
Sau đó, sửa đổi tệp bằng cách chọn một trong các tùy chọn sau:
. . .
#export JAVA_HOME=
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
. . .
. . .
#export JAVA_HOME=
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
. . .
Nếu bạn gặp khó khăn khi tìm những dòng này, hãy sử dụng CTRL + W để nhanh chóng tìm kiếm trong văn bản. Sau khi hoàn tất, hãy thoát bằng CTRL + X và lưu tệp của bạn.
Lưu ý: Đối với Hadoop, giá trị của JAVA_HOME trong hadoop-env.sh sẽ ghi đè bất kỳ giá trị nào được đặt trong môi trường bởi /etc/profile hoặc trong profile của người dùng.
Bây giờ bạn có thể chạy Hadoop:
- /usr/local/hadoop/bin/hadoop
OutputUsage: hadoop [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or hadoop [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--config dir Hadoop config directory
--debug turn on shell script debug mode
--help usage information
buildpaths attempt to add class files from build tree
hostnames list[,of,host,names] hosts to use in slave mode
hosts filename list of hosts to use in slave mode
loglevel level set the log4j level for this command
workers turn on worker mode
SUBCOMMAND is one of:
. . .
Đầu ra này có nghĩa là bạn đã thiết lập cấu hình Hadoop thành công để chạy ở chế độ độc lập.
Bạn hãy đảm bảo rằng Hadoop đang hoạt động bình thường bằng cách chạy chương trình MapReduce mẫu mà nó cung cấp. Để làm như vậy, hãy tạo một thư mục được gọi là input trong thư mục chính của chúng ta và sao chép các tệp cấu hình của Hadoop vào đó để sử dụng các tệp đó làm dữ liệu của chúng ta.
- mkdir ~/input
- cp /usr/local/hadoop/etc/hadoop/*.xml ~/input
Tiếp theo, bạn có thể sử dụng lệnh dưới đây để chạy chương trình MapReduce hadoop-mapreduce-examples, một kho lưu trữ Java với một số tùy chọn:
- /usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar grep ~/input ~/grep_example 'allowed[.]*'
Điều này giúp đỡ chương trình grep, một trong nhiều ví dụ có trong hadoop-mapreduce-examples, theo sau là thư mục đầu vào, input và thư mục đầu ra grep_example. Chương trình Grep MapReduce sẽ đếm các kết quả phù hợp của một từ theo nghĩa đen hoặc biểu thức chính quy. Cuối cùng, biểu thức chính quy allowed[.]* được đưa ra để tìm các lần xuất hiện của từ allowed trong hoặc cuối câu khai báo. Biểu thức có phân biệt chữ hoa chữ thường, vì vậy bạn sẽ không tìm thấy từ nếu nó được viết hoa ở đầu câu.
Khi nhiệm vụ hoàn thành, nó cung cấp một bản tóm tắt về những gì đã được xử lý và các lỗi mà nó đã gặp phải, nhưng phần này không chứa kết quả thực tế.
Output. . .
File System Counters
FILE: Number of bytes read=1200956
FILE: Number of bytes written=3656025
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=2
Map output records=2
Map output bytes=33
Map output materialized bytes=43
Input split bytes=114
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=43
Reduce input records=2
Reduce output records=2
Spilled Records=4
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=41
Total committed heap usage (bytes)=403800064
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=147
File Output Format Counters
Bytes Written=34
Lưu ý: Nếu thư mục đầu ra đã tồn tại, chương trình sẽ không thành công, và thay vì xem bản tóm tắt, đầu ra sẽ giống như sau:
Output. . .
at java.base/java.lang.reflect.Method.invoke(Method.java:564)
at org.apache.hadoop.util.RunJar.run(RunJar.java:244)
at org.apache.hadoop.util.RunJar.main(RunJar.java:158)
Kết quả được lưu trữ trong thư mục đầu ra và có thể được kiểm tra bằng cách chạy cat trên thư mục đầu ra:
- cat ~/grep_example/*
Output22 allowed.
1 allowed
Tác vụ MapReduce đã tìm thấy 19 lần xuất hiện của từ allowed, theo sau là dấu chấm và một lần xuất hiện khi từ đó không được phép. Việc chạy chương trình ví dụ đã xác minh rằng cài đặt độc lập của chúng ta đang hoạt động bình thường và non-privileged users (người dùng không có đặc quyền) trên hệ thống có thể chạy Hadoop để thăm dò hoặc gỡ lỗi.
Trong hướng dẫn này, bạn đã cài đặt Hadoop ở chế độ độc lập và xác minh nó bằng cách chạy một chương trình mẫu mà nó cung cấp. Để tìm hiểu cách viết các chương trình MapReduce của riêng bạn, bạn có thể truy cập Hướng dẫn MapReduce của Apache Hadoop, hướng dẫn này đi qua đoạn mã đằng sau ví dụ. Khi bạn đã sẵn sàng thiết lập một cụm, hãy xem Hướng dẫn Thiết lập Hadoop Cluster của Apache Foundation.
Nếu bạn quan tâm đến việc triển khai một cluster đầy đủ thay vì chỉ một cụm riêng lẻ, hãy xem Cách tạo một Hadoop Cluster với DigitalOcean Droplets.